Team Project (Unit 6)
Team Project
Group D's Track 1 Airbnb business analysis: classical machine learning (regression and clustering) applied to the AB_NYC_2019 dataset, delivered as a 1,000-word executive analytical report grounded in CRISP-DM and supported by an audit-trail decision register.
Module: Machine Learning, PCOM7E April 2026. Submission deadline: 23:55 UK Monday 8 June 2026. Group: D (six members), Track 1 (Classical Machine Learning - regression and clustering). Dataset: AB_NYC_2019 (Dgomonov, 2019).
Project summary
Track 1 of the Machine Learning module asked the team to apply classical ML (regression for price prediction and clustering for customer segmentation) to the AB_NYC_2019 dataset (Dgomonov, 2019) and to deliver a 1,000-word executive analytical report for Airbnb. The team’s chosen business question was: “Can Airbnb identify pricing patterns and listing segments in the NYC market to support hosts with competitive pricing and customise segment-specific guidance?” My role spanned project leadership, technical leadership and report ownership. The methodology is grounded in CRISP-DM (Chapman et al., 2000; Schröer, Kruse and Gómez, 2021), operationalised as a five-script Python pipeline with explicit ownership at each phase boundary. A handover-ready design document captures every methodological decision; an audit-trail decision register tags each decision under a three-tier justification framework (peer-reviewed literature, then recognised library documentation, then pragmatic with future-work framing). The deliverable was deliberately framed as decision support: not automated pricing or causal proof. Limitations are openly documented (2019 snapshot, listings are not guests, no booking data, correlation is not causation).
Learning Outcomes addressed
The team project addresses all four module learning outcomes. Per-artefact mapping appears in the Deliverables and Methodology sections below; the table here states the headline LO contributions.
| LO | How the Track 1 work evidences it | Primary artefacts |
|---|---|---|
| LO1 (legal, social, ethical, professional) | Limitations section explicit on fairness considerations (pricing models on observational data can entrench biases), correlation-not-causation framing (Leetaru, 2019; Chernozhukov, 2024), Leslie (2019) responsible-AI gating before deployment, and an explicit will-NOT-claim list rejecting Smart-Pricing prescriptive framing. | Limitations (Mella, 2026n); will-NOT-claim list. |
| LO2 (datasets, applicability, challenges) | Pre-committed six ML design constraints upfront (D-011: regression target = log1p(price), numeric encoding, zero-NaN modelling columns, outlier philosophy, scaling stage, provisional feature list), recognising the dataset’s right-skewed price, sparse review NaNs, and missing amenity data before cleaning began. Cleaning rules (Rules 2.1 to 2.7) each tagged to a Tier-1 academic citation. |
Decision register D-011 (Mella, 2026o); cleaning rules in briefing pack (Mella, 2026i). |
| LO3 (apply and critically appraise ML techniques) | Demand-mapping reframe (D-017) was a deliberate methodological pivot informed by the regression’s predictive ceiling: theory and practice critical thinking captured in real time in the decision register. Three-tier justification framework structurally interrupts “just-because” reasoning. | Demand-mapping pivot (Mella, 2026m); three-tier framework (Mella, 2026j); five-script pipeline (Mella, 2026l). |
| LO4 (effective member of a development team) | Designed a workstream split with a clear handover boundary; produced a self-contained briefing pack for a junior team member that pre-loads every cleaning rule with its academic citation, the three-tier framework, the deliverable specification and the quality checklist. Project lead, technical lead and report owner roles concurrently held; risks of role concentration acknowledged in the in-unit reflection. | Briefing pack (Mella, 2026i); design document (Mella, 2026h); decision register (Mella, 2026g). |
My individual contribution
My contribution to the Track 1 work spans five concurrent roles.
As Coordinator (the role formally added to the team’s role inventory at the 9 May meeting), I am accountable for general communications, the asset repository, scheduling, tooling, meeting facilitation and ensuring tasks land on time. In practice this has covered the Google Drive workspace setup with role-appropriate permissions (Mella, 2026r), hosting and facilitating both group meetings (kick-off 7 May; decisions 9 May), producing meeting presentations, notes and summary emails, producing the project plan and timeline (Mella, 2026s), and being the point of contact for clarifications and 1:1 interlocks during the per-workstream phase. I treat coordination as a substantive technical contribution, not as administrative overhead: the artefacts produced under that role are first-class evidence of contribution, comparable in weight to the modelling outputs themselves.
As project lead, I designed the workstream split (D-012, refined through D-013, D-015 and D-016) - delegating the data-cleaning piece to a junior team member while retaining the modelling and report ownership. The split was supported by a self-contained briefing pack (Mella, 2026i) which pre-decided every cleaning rule, pre-loaded the academic citations, and embedded the three-tier justification framework so the colleague could defend her work without re-deriving it.
As modelling lead (technical), I designed the five-script CRISP-DM-aligned Python pipeline (Mella, 2026l), committed the six ML design constraints upfront (D-011: Mella, 2026o), absorbed Phase 1 formal documentation and Phase 3 feature analysis onto my side (D-016) so the colleague’s brief could collapse to roughly 1,200 words without losing rigour, and re-anchored the analytical narrative from a Smart-Pricing-style framing to a demand-mapping plus competitive-map framing (D-017: Mella, 2026m) when the regression’s modest predictive ceiling made the prescriptive framing untenable.
As EDA and cleaning pre-run designer, I produced the pre-run design document (Mella, 2026p) and the cleaning script 02_data_preparation.py (Mella, 2026q) for the colleague leading the EDA and cleaning workstream. The design document defines the output specification for the cleaned CSV (zero NaN in modelling columns, log-transformed regression target via np.log1p, numerically encoded categoricals, q99-capped outliers in minimum_nights), seven cleaning tasks with Python code and literature citation each (Bishop, 2006; Brownlee, 2018; Crawford, 2006; Harmadi, 2021; Patil, 2018; Tukey, 1977; whyalwaysme, 2019), the standard EDA commands plus useful one-liners, the findings-document specification, and the folder-structure spec. The pre-run treats the CRISP-DM Phase 4 to Phase 3 feedback loop as a design constraint on Phase 3, rather than as a loop to be discovered reactively during modelling: a one-day investment to avoid a week of re-work mid-modelling. The cleaning script exists as a separate .py file because Word’s auto-correction of straight single quotes to curly quotes and occasional indentation loss on copy-paste produces Python syntax errors that look like brief errors but are tooling artefacts; the brief tells the reader to copy from the script, not from the Word document.
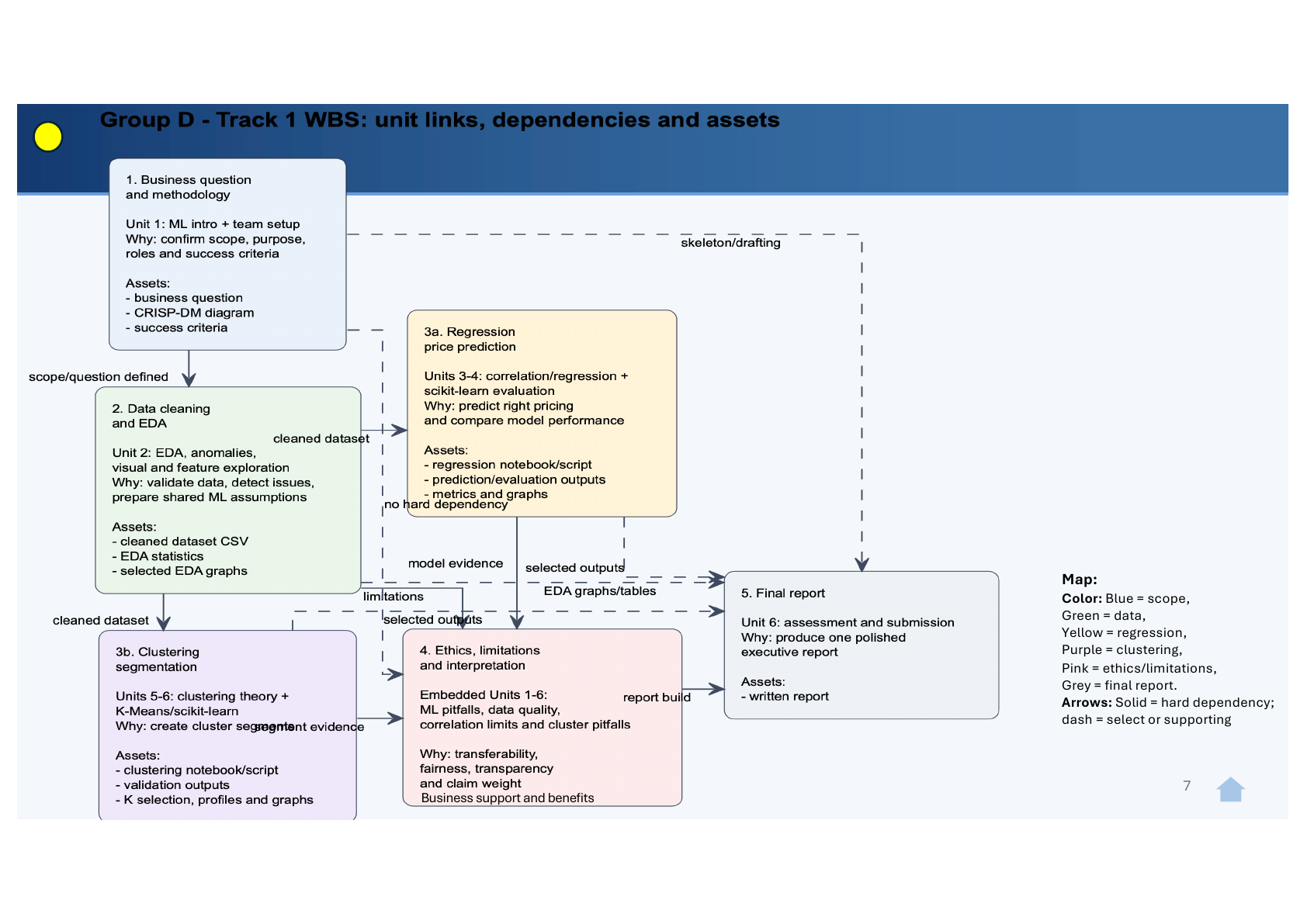
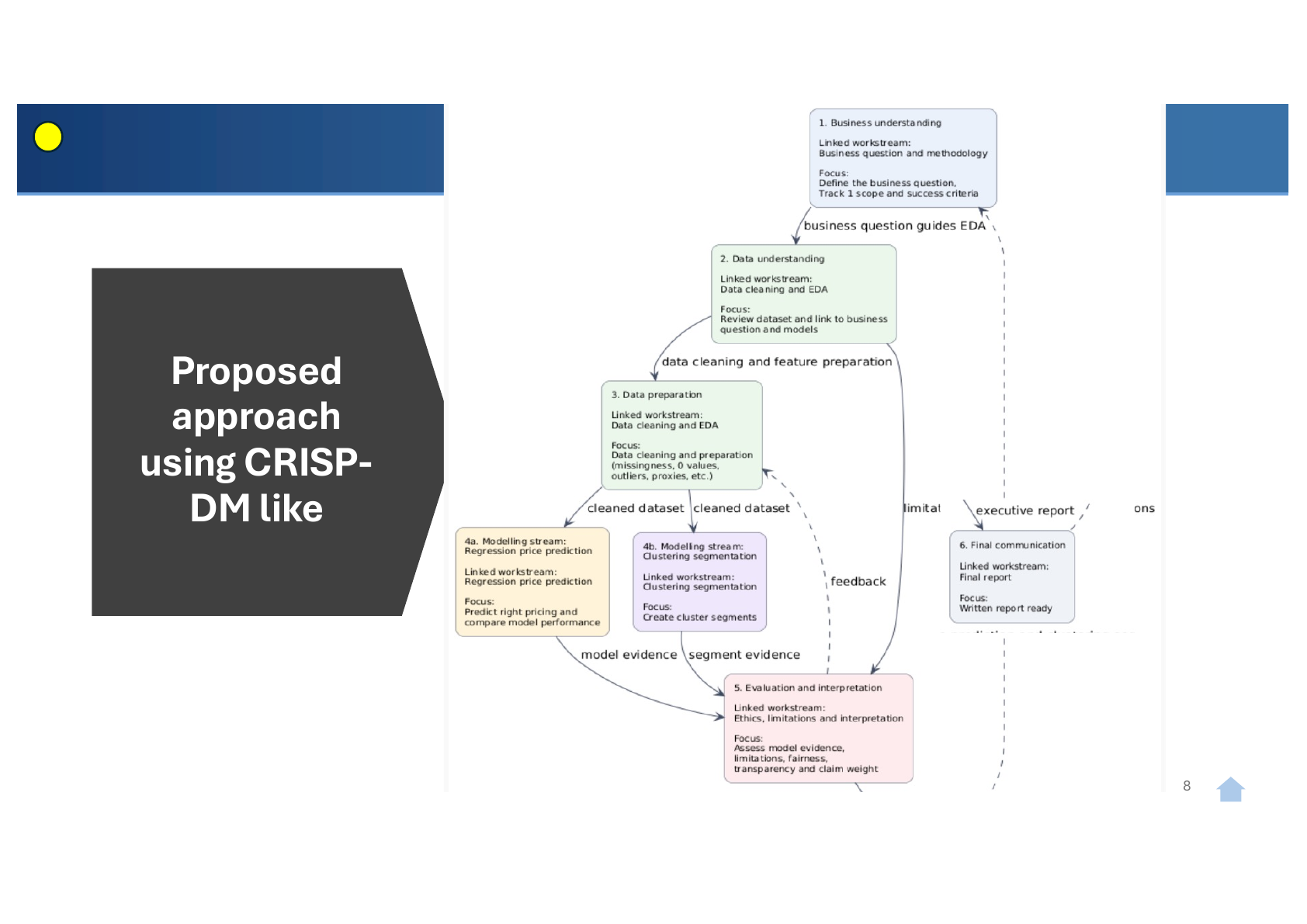
As report owner and integrator, I wrote the report skeleton (currently v0.0.10), pre-filled the methodology paragraph, recommendations framework and limitations section with locked content, and operationalised CRISP-DM with a four-paragraph treatment plus Figure 1 (D-018). The decision register (D-001 through D-019: Mella, 2026g; D-019 added in the 10 May 2026 update: Mella, 2026u) is the audit trail of every choice.
I am also the submitter for the team: the final submission action lands on me on 6 June 2026, two days before the 8 June 23:55 hard deadline.
Whilst the workload concentration on my side reproduced the pattern observed in the previous Intelligent Agents Group D project (D-012 acknowledges the risk explicitly: Belbin, 2010 on team-role concentration; Latane, Williams and Harkins, 1979 on social loafing as observed-in-context), this time the concentration was a deliberate design choice - informed by what I learned from the IA reflection - rather than a reactive compensation for under-delivering teammates.
Methodological rigour
The Track 1 work-stream stands on a small set of methodological assets that distinguish it from a typical assignment-completion exercise.
CRISP-DM operationalised as a five-script pipeline with explicit ownership. Phase 1 (Business Understanding) anchored on the locked business question plus the six ML design constraints upfront. Phases 2 and 3 delivered through 01_data_profiling.py and 02_data_preparation.py (data lead) and confirmed via 03_feature_analysis.py (project lead). Phases 4 and 5 integrated in 04_regression.py (linear, multiple, polynomial regression on log_price) and 05_clustering.py (K-Means, K from 2 to 6, elbow-selected). Phase 6 (Deployment / Communication) is the report and this e-Portfolio. Diagrammed in Figure 1 (Mella, 2026l).
The three-tier justification framework. Every methodological decision tagged Tier 1 (peer-reviewed literature or module reading list, preferred), Tier 2 (recognised library documentation or practitioner sources, when Tier 1 absent) or Tier 3 (pragmatic or common-sense, last resort, flagged with future-work framing). Project-internal rule that protected the report’s Criticality mark and prevented “just-because” decisions (Mella, 2026j).
The decision register (D-001 to D-018). Chronological audit trail of every methodological choice. Each entry captures: decision; alternatives considered; tier of evidence; citation; in-report visibility flag. This is the artefact that stops “we would never have known to look for that” objections at marking (Mella, 2026g).
The handover-ready design document. Synthesised by topic (project goal, methodology backbone, dataset specification, ML design constraints, cleaning decisions, feature engineering, regression handover, clustering handover, pipeline contract, reflection-in-report mapping, open questions, references). A different team member could pick up the work using only this document plus the cleaned CSV (Mella, 2026h).
The triple-source evaluation map. Mapping each report section against three concurrent evaluation sources: the assignment brief, the tutor’s structure guidance, and the PG Grading rubric for Technical Reports. Pre-empts the “we hit the brief but missed the rubric” trap (Mella, 2026k).
The principal CRISP-DM iteration (Phase 5 to Phase 1, captured as D-017). The demand-mapping reframe. An early Smart-Pricing-style framing was re-evaluated against the regression’s modest R-squared and re-anchored as demand mapping plus a peer-anchored competitive map for hosts. This is the iteration narrative that lands in the methodology section of the report and demonstrates theory-and-practice critical thinking (Mella, 2026m).
The will-NOT-claim list. Defensive criticality. Names what we explicitly do not claim from this analysis: no amenity recommendations, no listing-description NLP, no seasonal pricing, no per-host commands, no precise booking-conversion forecasts, and explicitly not a Smart-Pricing product. Pre-empts over-claim risk and earns Criticality marks for honesty (Mella, 2026n).
Meeting notes
Chronological record of team meetings with attendance, agenda, decisions and action items. Each meeting note carries an evidence identifier and is referenced from the Evidence Index.
7 May 2026 - Group D kick-off (Zoom, 14:00 UK)
Brief notes; full slides on the Unit 2 page. Attendance: 4 of 6. Outcomes: working agreement direction agreed, communication and tooling proposals agreed, submission scope agreed, Coordinator role confirmed.
9 May 2026 - Group D decisions meeting (Zoom, 14:00 UK)
Attendance: 3 of 6. One absent member confirmed asynchronously (via WhatsApp) that decisions could proceed without him; the remaining two received the meeting-summary email with all relevant assets and an explicit invitation to feed back or counter-propose.
Pre-agreed rule applied: attendees lock decisions on workstreams, business question, roles and task allocation; meeting outcomes are documented and circulated by email within hours; absent members retain voice via asynchronous review.
Outcomes locked at the meeting and circulated same-day (Email of record - 9 May 2026 meeting summary; Mella, 2026t):
- The business question, captured on its own slide (Mella, 2026v):
- The Coordinator role formally added to the team’s role inventory (Decisions and definitions slides; Mella, 2026t).
- The project plan locked through to submission on 6 June 2026 (Mella, 2026s).
- Task allocation: Francesca on EDA and Cleaning by 16 May; Ariel on Modelling by 23 May, Report by 27 May, Submission on 6 June; Sarra and Tamim on QA by 5 June.
The full 12-slide meeting deck with team status, business question, activities, roles, dependency map, CRISP-DM operationalisation, timeline and wrap-up is available on request and catalogued in the Evidence Index (download the 12-slide deck; Mella, 2026w). Three slides are reproduced below as anchored figures because they carry direct evidentiary value for LO4 and LO3.

This was a Tier-3 pragmatic decision with explicit future-work framing: the attendance asymmetry was real, the rule applied was defensible (decisions documented and circulated; async review opportunity preserved), and the alternative (postponing to wait for full attendance) would have compressed the EDA and cleaning window and risked the modelling-stage deadline.
10 May 2026 - EDA and cleaning pre-run handover to Francesca
The pre-run handover email to the workstream lead is captured in Email of record - 10 May 2026 EDA pre-run handover (Mella, 2026x). The email delivers three artefacts: the Drive folder structure with role-appropriate permissions (Mella, 2026r), the pre-run design document (Mella, 2026p), and the cleaning script 02_data_preparation.py provided as a separate file because of the Word smart-quote risk (Mella, 2026q). Target completion 16 May 2026.
(Further meeting notes added as the project progresses through the per-workstream interlock phase and the 23 May next group meeting.)
Peer feedback
Feedback received from team members during the project. Anonymised; original artefacts held in the working record.
The first peer acknowledgement on 8 May 2026 is logged on the Feedback page. Further peer feedback added as it arrives.
Tutor feedback
The first tutor commendation on 5 May 2026 is logged on the Feedback page. Further tutor feedback added as it arrives.
Deliverables
| Artefact | What it is | What it evidences | Reference |
|---|---|---|---|
| Team analytical report | 1,000-word executive report (.docx and .pdf) | LO1, LO2, LO3 | (in progress, lands at the 8 June deadline) |
| Five-script Python pipeline | 01_data_profiling.py to 05_clustering.py |
LO2, LO3 | (Mella, 2026l) |
| Cleaned dataset | AB_NYC_2019_cleaned.csv |
LO2 (applied data-quality treatment) | Colleague’s deliverable |
| Decision register | D-001 to D-018, audit trail of every methodological choice | LO3 (critical appraisal) | (Mella, 2026g) |
| Design document | Handover-ready synthesis with full pipeline contract, regression specification, clustering specification, figure ownership inventory | LO2, LO4 | (Mella, 2026h) |
| Briefing pack to colleague | v0.6 self-contained Word document for the data-cleaning lead | LO4 (virtual team leadership) | (Mella, 2026i) |
| Three-tier justification framework | Project-rule document tagging every decision T1, T2 or T3 | LO3 (systematic reasoning) | (Mella, 2026j) |
| Triple-source evaluation map | Mapping of every report section against the brief, the tutor’s structure guidance and the PG Grading rubric | LO3 (disciplined preparation) | (Mella, 2026k) |
| Pre-run design document for EDA and cleaning | Output specification, seven cleaning tasks with literature citations, exploration step, findings-document spec, folder-structure spec | LO2 (datasets), LO4 (handover-ready artefact) | (Mella, 2026p) |
Cleaning script 02_data_preparation.py |
Imports, raw CSV load, Tasks 2.1 to 2.8 in order, produces cleaned CSV and step-2 cleaning log; provided as a separate .py file as a defensive countermeasure against Word’s smart-quote and indentation issues |
LO2, LO3 | (Mella, 2026q) |
| Group D Google Drive workspace | Workstream-driven folder structure with role-appropriate access permissions and explicit sharing policy | LO4 (operational discipline) | (Mella, 2026r) |
| Group D project plan and timeline | Locked, owner-named milestones with input and output columns through to submission on 6 June 2026 | LO4 (project management) | (Mella, 2026s) |
| 9 May meeting notes and summary email | Full distribution-list email circulating the locked business question, timeline, task allocation and Coordinator role | LO4 (transparent decision-making) | (Mella, 2026t) |
| Decision register entry D-019 | Pre-run design document issued; Coordinator role explicit; timeline locked; partial-attendance rule applied | LO3 (decision audit) | (Mella, 2026u) |
| Figure 1 - CRISP-DM operationalised diagram | Five-script pipeline overlaid on CRISP-DM phases with ownership colour-coding and labelled feedback loops | LO2, LO3 | To be generated at report-drafting time |
Project plan and timeline
The locked, owner-accountable plan from kick-off through to submission, agreed at the 9 May meeting (Mella, 2026s):
| By | Task | Owner | Input | Output |
|---|---|---|---|---|
| 16 May | EDA + Data Cleaning | Francesca | Raw dataset; pre-run design and plot/chart ideas from Ariel | Cleaned dataset CSV; design decisions and findings; charts/plots; Python scripts |
| 23 May | Regression and Clustering | Ariel | Cleaned dataset, business question, EDA signals, pricing target, selected variables | Python scripts, prediction/evaluation outputs, metrics and graphs, segmentation/validation outputs, K selection, profiles |
| 27 May | Written report | Ariel | All previous outputs | Pre-final written report |
| 5 June | QA and review | Sarra and Tamim | Pre-final written report and all assets | Final-reviewed report |
| 6 June | Submission | Ariel | Final-reviewed report | Submitted |
The plan makes the dependency chain visible to all members: EDA and cleaning is on the critical path for modelling, modelling is on the critical path for the report draft, the report draft is on the critical path for QA, and QA outputs feed submission. The dependency chain is the operational form of the CRISP-DM phase ordering, and a missed milestone in the early weeks cascades through every downstream step. The plan is the artefact that makes the cascade legible.
Asset repository (Google Drive workspace)
The workspace is structured under a Group D root with workstream-driven sub-folders (Mella, 2026r): Meeting Minutes, Business Question and Decisions, Timeline and Task Allocation, EDA and Data Cleaning (with Findings document, Cleaned dataset and logs, Python scripts sub-folders), Modelling, Report, QA and Review.
Differentiated permissions: the Coordinator (Ariel) has editor access across the workspace; the workstream lead (Francesca for EDA and cleaning) has owner access on her sub-folder and editor access elsewhere; other members have read access by default with edit access on their respective workstream folders when those start. A small number of links are shared on “anyone with the link can view” for members without Google accounts, bounded by an explicit policy in the meeting-summary email asking that links not be shared outside Group D.
The arrangement was documented in the meeting-summary email (Mella, 2026t), so the access model is itself an audit-traceable artefact.
Communications cadence
Three project emails to date establish the written communications cadence:
- Email 1 (8 May, post-kick-off, to the full group of six) - “Group D - kick-off recap, drive setup, next steps”. Established the asset repository convention, circulated the meeting recording and presentation, scheduled the next meeting, invited absent members to feed back asynchronously, and added a security note on link sharing.
- Email 2 (9 May, post-decisions meeting, to the full group) - “Group D - Meeting on May 9th - meeting notes, definitions, next steps”. Circulated the locked business question, the locked timeline, the locked task allocation, the meeting recording and the security note. Confirmed the next group meeting date (23 May) and the move to per-workstream 1:1 interlocks for the active week.
- Email 3 (10 May, to Francesca, cc Sarra) - “EDA and Data cleaning design pre-run”. Handed over the three-artefact pre-run pack (folder, design document, script) with a target completion date (16 May) and an open offer for ad-hoc clarification.
The cadence has two practical functions: first, it captures decisions in a timestamped, named-recipient record that is cheap to revisit later; second, it removes ambiguity for absent members, who can read the summary and respond without needing a 1:1 catch-up. Structured written communication is treated here as a form of risk reduction: most coordination problems start as small ambiguities, and a written cadence is the cheapest available place to surface and resolve them.
Comparison against the Individual Project (Unit 11)
The explicit comparison between the team project (Unit 6) and the individual project (Unit 11) lives on the Project Comparison page, as required by the assignment brief.
References
Inline citations on this page resolve to the consolidated References page. Self-authored evidence items use the (Mella, 2026X) form with letter suffixes; the Evidence Index is the navigational catalogue.